《论语》TTS有声版发布啦!
缘起
《论语》有声版?难道还不够多吗?
同样的问题,它的父项目《一瓶论语》在“前言”和“使用说明”里作了回应。有声版呢?还是用软件读?开玩笑吧?
真人有声版《论语》的确不少,有些还提供免费下载。与它们相比,这个TTS有声版的主要优点,一是中立,二是扎实,三是自动化。至于开源项目的天然优势,比如容易及时更新,已经在《一瓶论语》里说得很详细。
“TTS”是“Text to Speech”的缩写,它通过软件自动把文字内容“合成”为语音信号,直接“读”出声音或者保存成音频文件。2个多月前,我偶然被自己安卓手机上“Google文字转语音引擎”朗读中文网站文章的质量吸引,自然就想到,用它读文言文会怎样呢?有可能流畅自然地朗读《论语》吗?这种人文和一点点技术相结合的题目,总让我兴趣盎然,《论语》TTS有声版就是后来不断试验的一个小结。
让人开心的是,只要不太多的辅助,Google TTS就能把2500年前的文言文读得像模像样。请试听一下:
这里的辅助工作,主要是帮助TTS引擎断句,还有多音字和难字的辨析。然后,就可以把整个的“台词”交给TTS引擎自动处理了。更棒的是,安卓系统开放了TextToSpeech开发接口,尽管控制的范围不如我希望的丰富,但也足以按章朗读,统一合并,然后自动生成播放列表和同步字幕了。限于时间,我只用Google TTS做了试验。其它优秀的TTS引擎,比如科大讯飞,相信也会有出色的表现。
显然,与真人相比,Google TTS的“播音腔”没太有感情,也缺乏变化。换一个角度想,对于《论语》来说,这正是它的独特优点。《论语》是中国传统文化的精华,每个人心中都应该为它留出方寸之地,不断咀嚼玩味,形成独立的理解。一个值得反复聆听的“标准”有声版,就应该字正腔圆,不带主观色彩,对原文一视同仁,没有分心的背景音乐。对于《论语》,这种去掉阅读者“理解”和其它修饰的朴素版,似乎更容易激发听者自身的共鸣,缩短从声音到心灵的距离,而不会一遍惊艳,两遍三遍不过尔尔,然后束之高阁,甚至有所厌弃。这就是软件朗读“中立”的意义。
诚然,目前的阅读效果还有不少不太自然的地方(见后面的已知问题)。如果你把TTS引擎当成一个刚认字的孩子,虽然还不太理解《论语》的含义,仍在努力把它读顺(而且会越来越顺!),感受就会好得多。我在这两个月里听过不下100遍,仍然兴味盎然,似乎可以作为一个佐证。
这个《论语》TTS有声版,就是希望成为一个反复可听、持续改进的“标准版”。而且听得多了,总会有自己朗读一个“完美版”的创作冲动。我当然希望看到更多严谨到位的真人版不断问世。
文本和音频
本项目的主要内容是两个文本文件:
- ly.txt:从《一瓶论语》自动提取的《论语》原文,作为TTS引擎“台词”文本的基础,并用来制作字幕。
- ly-tts.txt:TTS引擎的“台词”文本,所有的手工修改都是在它上面进行的,最后送入TTS引擎,生成前面的音频文件。
如果让TTS引擎直接朗读ly.txt,最明显的问题就是很多多音字、难字都读错了,所以要找读音确定的同音字来替换。为了不影响TTS分词的效果,应该尽量考虑所用字的词性和含义。同等条件下,选择原文没用过的字也许好一些。这个列表比较长,放在了附录的字词替换表中。
现在每个字都能正确发音了,连起来一听还是怪怪的,原因就在于断句。《论语》毕竟是2500年前的古汉语,我们现代人如果只看白文版,也很难一次读通顺,何况是对古文所知寥寥的软件呢?所以,需要选择性地插入或者删除一些标点符号,给TTS引擎足够的提示。这里占用的时间最多,需要反复修改比对。传统的“句读”(dòu)是从段落中分隔出句子(添加。?!等),从句子中分隔出“子句”(添加,;、等),这里的粒度更细,要在连读错误的“子句”内部分隔词组。古汉语的一个显著特点是单字成词,所以TTS引擎的很多先验知识就不成立了。断句的处理包括:
- 删除:“ ” ‘ ’ 《 》
- 替换:: → ,
- 选择性替换:、 → ,
- 选择性添加:,’(短间隔,用于长难句的句读)
举例来说,1.6章的“弟子入则孝,出则悌”,如果不在“子”、“入”之间加一个短间隔,就会把“弟子入”连读,“入”的发音既轻且短。短间隔’的停顿比顿号更短一些,是我经过试验发现的,其它的TTS引擎未必表现相同。如果TTS引擎允许在文本中直接插入描述性标记,比如间隔时间、汉语拼音、轻重,甚至语气、场景等,用起来可以更灵活。
至此,用阅读软件打开ly-tts.txt,就可以调用Google TTS引擎,随点随读或者导出音频了。目前Google TTS的普通话语音数据包还只有女声一种。需要特别表扬的是,2017年12月更新的程序及其数据包比之前的效果进步明显,发音和断句更自然,读错的字也少了很多。可以预期,随着技术的演进,这个TTS版的质量也会持续提高,越来越接近“完美中立”的目标。
考虑到现代文和文言文的差异,朗读前会把所有的逗号、分号替换成句号。本项目发布的ly-tts.mp3,使用了0.9倍的阅读速度,总长度是108分钟出头,或者说6496秒。一些地方听起来会显得稍赶,但我觉得,《论语》这样的经典文本,就应该听到熟极而流的程度,所以没有再作调整。大家当然可以根据自己的喜好选择阅读速度,或者进一步修改,比如整体调高音调,变成童声的效果。
为了便于生成播放列表和字幕,我从每一章分别导出wav文件(synthesizeToFile),用sox在各文件末尾增加0.25秒静音后,合并成单个wav,最后用ffmpeg转换成mp3。对于有声书来说,32 kbps和64 kbps都是常见的选择,考虑到频繁的静音间隔,32 kbps VBR的表现我觉得已经挺好了。最后的文件体积约为25 MB。
播放列表和字幕
出于对目录的偏爱,我还制作了详细的播放列表(cue)、歌词(lrc)、字幕(srt),放在本项目附带的subtitles.zip里。它们都是从ly.txt和sox处理后的多个wav文件自动生成的,没什么稀奇之处,这里只展示一下使用效果。
Windows上,我喜欢用foobar2000播放音频。可以用它打开播放列表ly-tts.cue,并在旁边同步滚动歌词ly-tts.lrc(需要Lyric Show Panel 3插件):
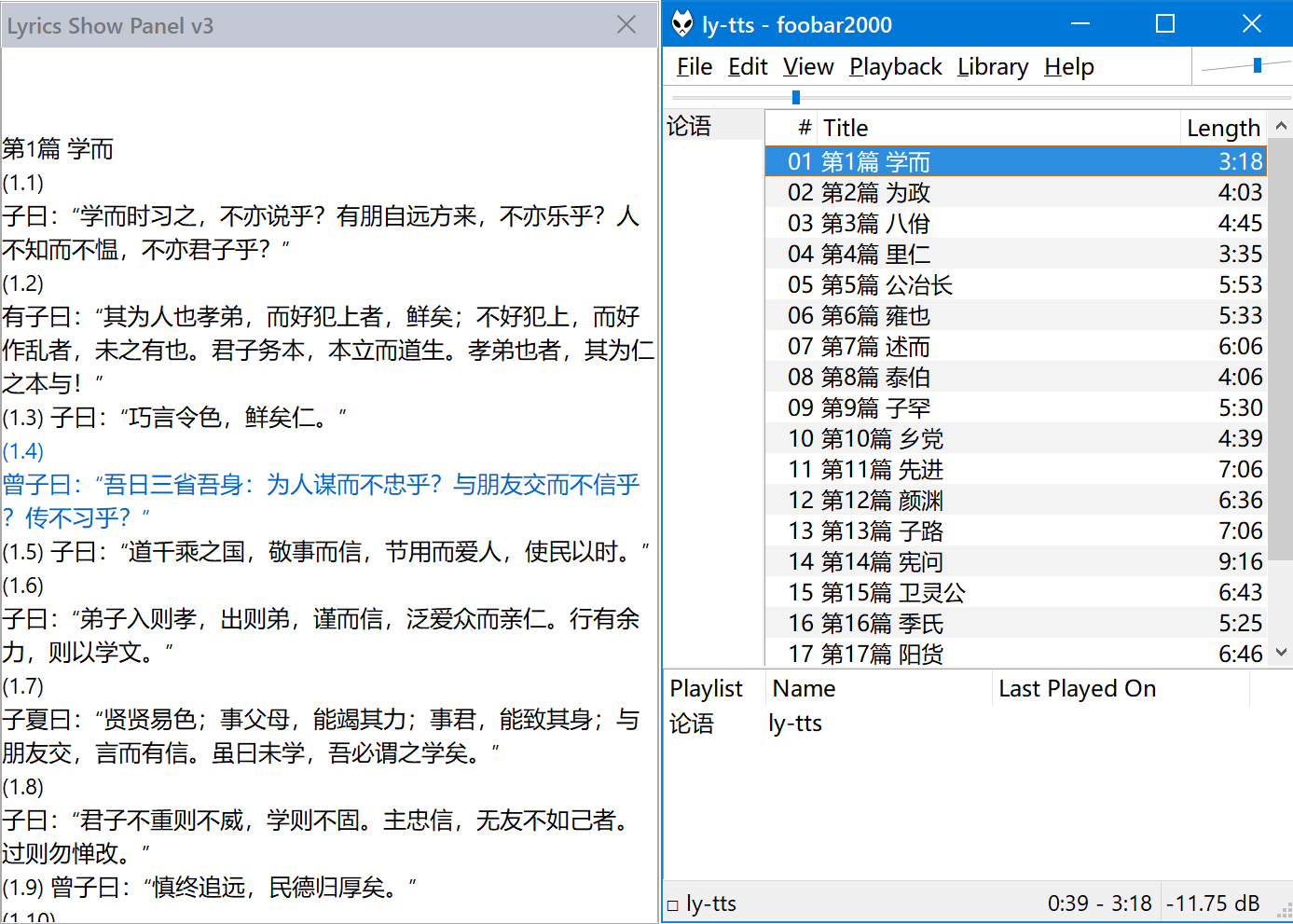
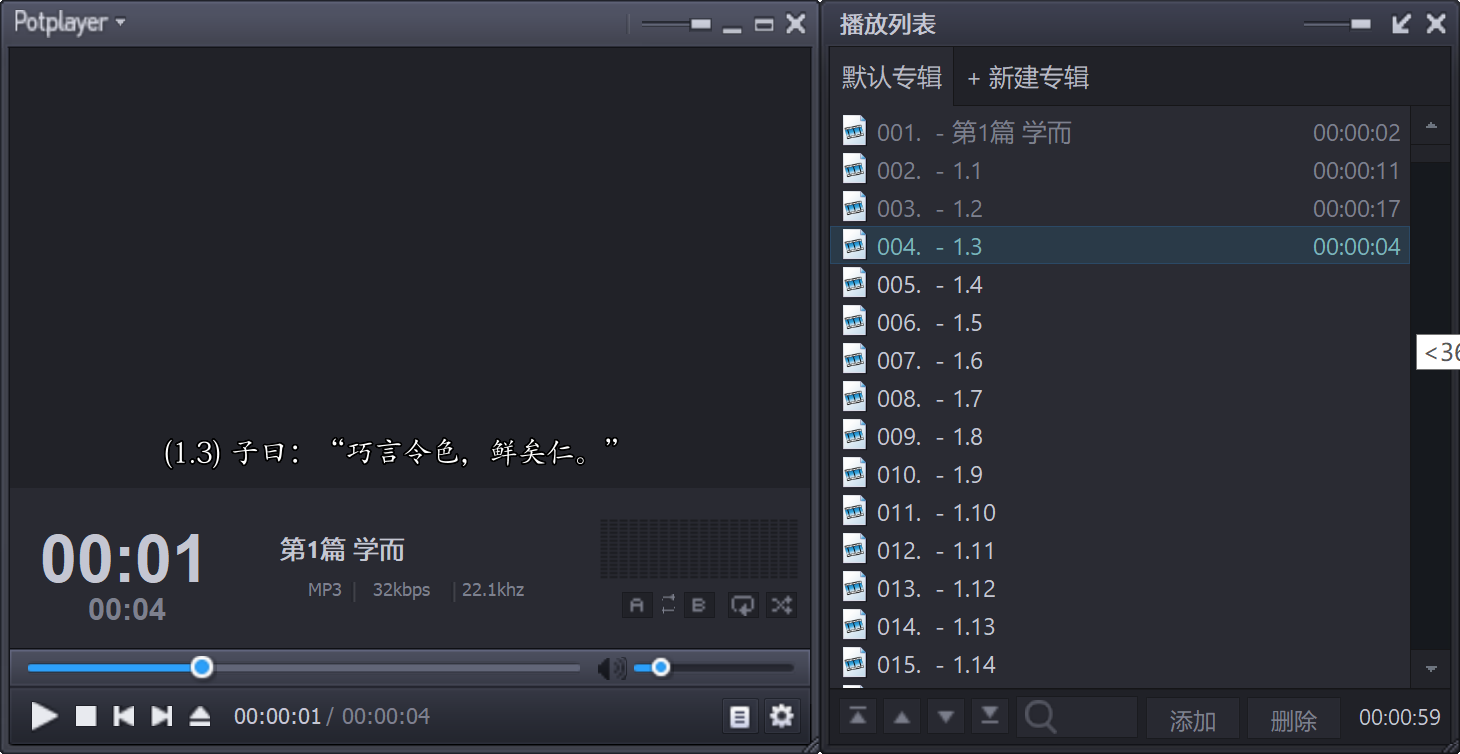
foobar2000目前严格遵循“最多99首歌”的播放列表规则,所以没法打开精确到章、总共“532首歌”的ly-tts-detailed.cue。【2018-2-4更新:从v1.4 beta2起,foobar2000将cue播放列表的曲数上限提高到999。】如果用PotPlayer,就没有这个限制,而且它既可以用ly-tts.lrc,也可以用ly-tts.srt当字幕,全屏观看的效果是很好的:
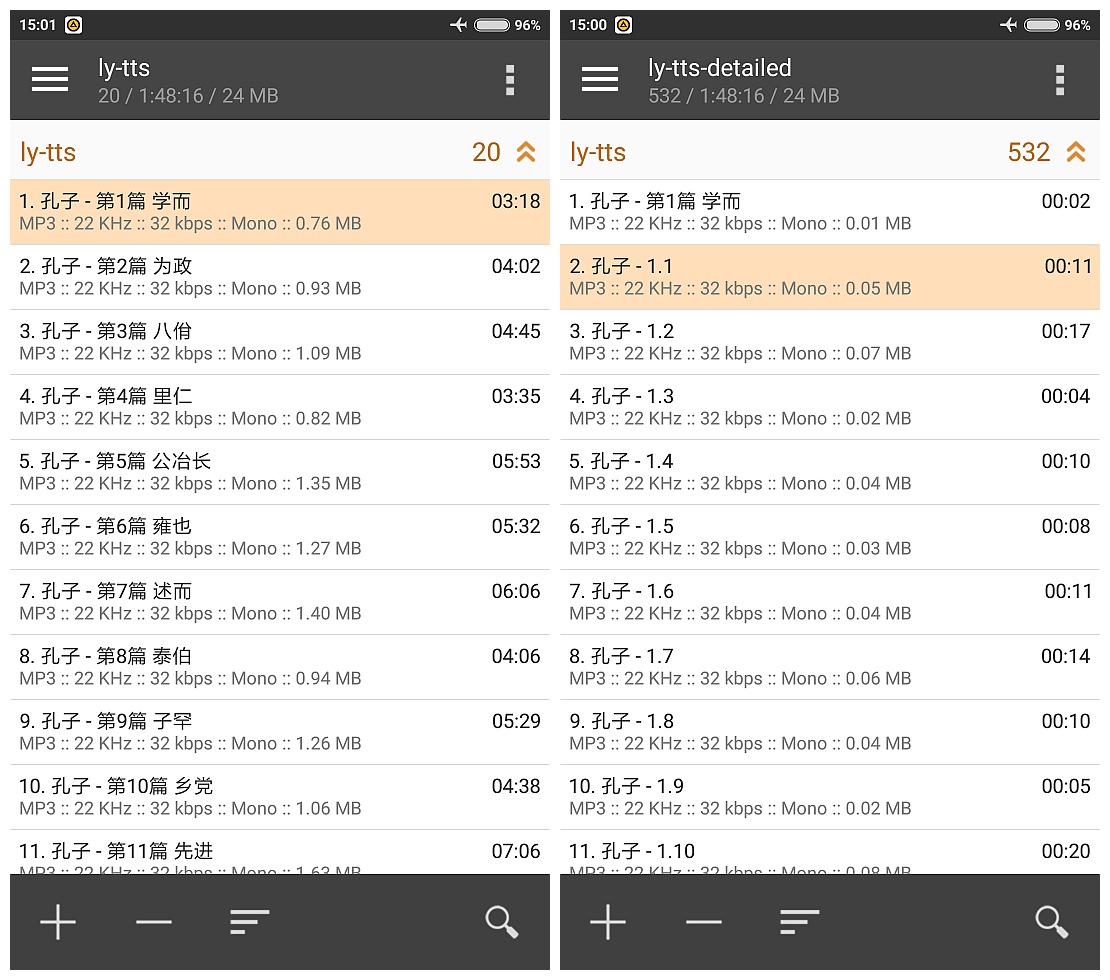
安卓手机上,AIMP支持cue播放列表,可惜还不支持同步歌词:
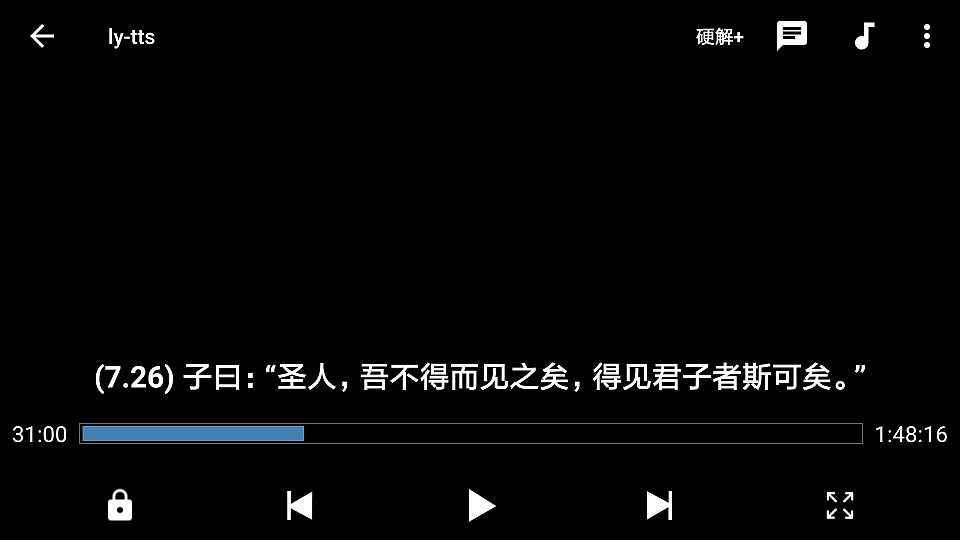
MX Player则支持同步字幕ly-tts.srt:
其它平台上,想必也有比较合理的解决方案。
已知问题
平心而论,目前这个版本的阅读效果不乏惊艳之处,但总有一些明显不够流畅自然的地方,记录在这里,希望可以在后续的程序和数据包中得到改进。
发音偏轻,长度偏短
- 1.14,“就有道”的“就”,应该是没有被理解为动词approach,而是副词just。相比之下,12.19的“如杀无道以就有道”,16.1的“陈力就列”,因为是连在一句内,就稍好一些。
- 5.7,“由也耗勇过我”的“过”,没有被理解为动词exceed,而是当成副词ever,读得偏轻偏短。另外一些“过”也有这个问题,尤其是句子结尾的“有过”,包括7.31“苟有过”,20.1“百姓有过”。
发音偏重
- 8.21,“悱饮食而致孝乎鬼神,恶衣服而致美乎黻冕,卑宫室而尽力乎沟洫”的3个“乎”。
字间隔偏长
这是“子句”内的字之间,间隔偏长的情况:
- 1.13,“言可复也”,句末的“也”,没有很好地作为助词处理,在前面多加了一个小间隔。其它的例子包括4.5“是人之所欲也……是人之所悟也”,6.15“非敢后也”,7.28“智之次也”。
- 2.18,“干禄”,也许是“干”没有被当成动词?
- 3.21,“夏后氏”,没有理解“夏后”是独立的姓氏,导致“氏”之前的间隔较长。16.1“季孙之忧”的“季孙”也是这样。
- 7.7,“束脩”,似乎没有被当成独立的名词,两个字的间隔略长。
- 19.23,“室家”,“而入”。
句间隔偏长
这是“子句”之间间隔偏长的情况,就像我们自己读文章,“一口气没接上来”:
- 1.10,“夫子’温、良、恭、俭、让’以德之。夫子之求之也……”,两句的间隔比正常情况偏长。
- 14.18,“与文子同升诸公。子闻之”。
- 16.1,“而必谓之辞。丘也闻”。
通过调整标点,一定程度上解决了其它若干处问题:
- 9.10,“子见资摧者、冕衣常者’与瞽者,见之”,“见之”之前。改成“资摧者,冕衣常者,与瞽者”,则好一些。这应该是添加’的副作用。
- 11.26,“子路、增皙、冉有、公西华侍坐。子曰”,“子曰”之前。把人名间的顿号改为逗号,虽然拖沓了一些,但消除了这个长间隔。
- 12.11,“子不子,虽有粟”。把原来的顿号都改成逗号,就消除了这个长间隔。
连读颤音
这种情况,大多数与w、u、o、y音有关。
- 4.7,“人之过也”的“过”。其它的例子包括14.13“以告者过也”,16.1“且尔言过矣”,19.8“小人之过”,19.12“言游过矣”,19.21两处“过也”。
- 5.12,“加诸我也”的“我”。其它的例子包括6.9“复我”,7.11“惟我”,7.16“于我如浮云”,9.11“博我以文,约我以礼”,11.4“回也非助我者也”,11.11“非我也”,13.10“苟有用我者”,17.1“岁不我与”,17.5“召我”、“用我”。
- 8.6,“不可夺也”的“夺”。
- 11.26,“唯国以礼”的“国”。
- 12.10,“是惑也”的“惑”。
- 14.11,“则优”的“优”。
- 14.34,“或曰”的“或”。
- 16.5,两处“三乐”的“乐”,过渡不够自然。
- 17.20,“辞以疾”的“以”。
- 19.1,“丧思哀”的“哀”。
句末短音
- 2.4,“七十而从心所欲不逾矩”的“矩”,听起来有点像读成了jù,但换成“举”、“沮”等同音字也一样,所以并不是读错了。真人朗读经常也会这样:因为“矩”处于整章结尾,如果这个字并不特别重要,往往会结束过快,切掉靠后的音节长度,效果接近于轻声,听起来像是第4声。如果有选项控制一个字发音饱满就好了。另一个例子是3.22“邦君为两君之好”,“好”也有点像第4声。
错读无替换
- 1.15,“如切如磋”的“切”读为qiè,而且没有读qiē的字可以替换。这个问题已经向Google提交了反馈,目前只得手工修改1.15导出的wav文件(唯一需要手工修改的地方)。方法是,用同样的配置朗读“正切如磋”(此时读为qiē),截取后三个字的波形,替换原来的三个字。
附录:字词替换表
- 说:悦
- 弟:悌
- 好:耗
- 鲜:显
- 与:欤,预
- 女:汝
- 省:醒
- 道:导
- 乘:剩
- 没:殁
- 共:拱
- 曾:增
- 知:智
- 阙:缺
- 相:象
- 乐:跃
- 宁:泞
- 亡:无
- 监:鉴
- 大:太
- 处:楚
- 朝:昭
- 放:仿
- 参:身
- 逮:待
- 妻:器
- 几:机
- 给:挤
- 斐:匪
- 少:邵
- 恶:悟,乌
- 孙:逊
- 衣:翼
- 澹:谭
- 语:遇
- 识:制
- 和:贺
- 校:较
- 间:鉴
- 钻:躜
- 予:余
- 贾:古
- 缊:愠
- 便:骈
- 躩:攫
- 蹜:宿
- 绤:细
- 冠:关
- 衰:摧
- 讱:韧
- 鞟:廓
- 陶:姚
- 乡:向
- 中:重
- 长:掌
- 齐:斋,资
- 见:现
- 期:基
- 丧:桑
- 夫:扶
- 率:帅
- 莫:暮
- 数:硕,树
- 柏:摆
- 塞:腮
- 得:德
- 小子:小紫
- 陈成子:陈成紫
- 韫:蕴
- 屏:禀
- 貉:河
- 裳:常
- 硁:坑
- 斗:抖
- 行:型,沆
- 占:沾
- 偲:思
- 南宫适:南宫括
- 裨:皮
- 要:邀
- 召:劭
- 被:披
- 发:珐
- 辟:避
- 蒉:篑
- 荷:赫
- 难:婻
- 陈:阵
- 遂:碎
- 卷:呟
- 薄:伯(Google TTS读为báo,共2处:8.3“如履薄冰”、15.15“薄责于人”。按商务版《现代汉语词典》、《现代汉语学习词典》,读bó为宜。)
- 归:馈
- 时:伺
- 亟:气
- 佛:必
- 沮:巨
- 蓧:钓
- 食:饲
- 泥:腻
- 更:耕
- 量:梁
- 磷:赁
- 曲:屈
- 菲:悱
- 侗:僮
- 华:花
- 栖:西
- 揭:弃
- 徼:焦
- 一:衣,宜,意
- 为:唯(do, be, fake, by, end-of-sentence aux.),谓(for, because, help)
- 有:又
- 杀:晒